My C-fu is very rusty but I wonder if you can extend the physics system class to have some custom destruction behavior just for your JNI layer. JNI to C++ was always way more “fun” than straight C.
…but I think you really start to get to the point where you are extending every class to wire up some things like that. (And maybe that becomes true anyway.)
Yeah, a concurrent hash map from ragdoll to physics system might work. Generic enough, it could be used for any ordered dependencies. (Just have to be careful of cycles in the general case.)
if you pass a strong reference to the the cleaner runnable for example it should keep the physics space alive until all cleaner actions have been executed.
I like this idea. It’s simpler than the static map, very elegant.
I don’t know much about the JIT. Is there some way to prevent optimization in this particular case? For instance, would passing the reference to native code be sufficient?
Most of the time folks find cases of “hotspot broke my code”… it’s actually something else.
I give the JMH guys the benefit of the doubt because I don’t have time to look deeper… but even that’s a little sus. However, what they are trying to do is going to provoke the beast no matter what. There is also the assumption that “they know what they are doing”. (But in my life I found bugs in the JDK itself so…)
Regardless, strong references should be strong. JIT/Hotspot should not remove them because it can’t possible know “everything that is about to come”. Hotspot has more information on actual use but it’s also supposed to fallback to the original code if something triggers a different use than expected. (It’s been probably 10 years since I poked around in the JVM and hotspot code, though.)
In this case, don’t worry about it until there is cause to worry about it… then assume that it’s literally anything else until you can prove otherwise.
I haven’t seen the implementation yet so I can’t comment… but if it’s somehow retrievable (ie: not private final and never used or accessed through getters) then I could “maybe” see it.
…but something is going to clear it later, I imagine. So it IS used on some level.
Afaik we are talking about a Runnable passed to a java.lang.Cleaner. (At least currently stephen is using that) Keeping the reference to the physics space alive as long as the object exists to avoid that the physics space get’s GC’ed first. No need to clear it. and could be a lambda or whatever.
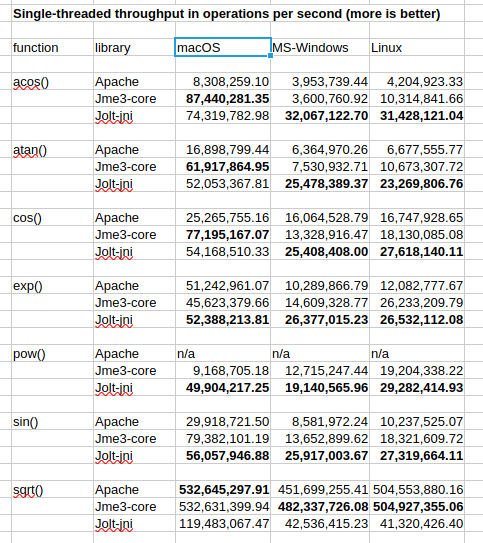
For reasons of convenience and portability, jolt-jni provides single-precision methods to calculate transcendental functions (like sqrt() and acos()). These methods invoke the standard C++ libraries via JNI.
For many weeks I’ve been curious how these methods compare with the corresponding methods in JME’s FastMath class. Today I went off on a wild tangent, creating a small benchmark to satisfy my curiosity. For fun, I included the Apache Commons Mathematics Library and ran the benchmark on 3 different operating systems.
Here are the highlights:
Jolt-jni’s single-precision transcendentals were fastest in most cases, for all functions except sqrt(). The exceptions were the acos(), cos(), and atan() functions on macOS, for which jme3-core was slightly faster.
On sqrt, Jolt-jni was slowest. There jme3-core was fastest on Windows and Linux. It tied with Apache on macOS.
I was very surprised by these results. I expected Apache’s fancy library to outperform jme3-core, which basically invokes the double-precision methods in java.lang.Math and rounds off the results.
I realize JVM microbenchmarking is tricky, and I may have screwed up. Feel free to look at my source code and tell me what I might’ve done wrong.
I realize transcendentals shouldn’t be a major performance factor in most Java games. (If you use trig functions in a JME game, you’re probably doing something wrong.)
I haven’t tested Jolt-jni transcendentals for accuracy and corner cases, so there might be non-performance reasons to avoid them.
But still … if you really care about transcendental performance, you ought to consider Jolt-jni … even if you don’t need physics!
On my machine (windows, amd threadripper gen1, jdk 23) jme is fastest everywhere. I kind of expected jni to be slower so i was surprised when i saw your results.
Jolt-jni v0.9.5 and KK Physics 0.3.1 were released today.
The motivation for jolt-jni v0.9.5 was to add Android support. Nobody asked for this. I wanted to figure out how to automate building/publishing Android native libraries without relying on Travis CI. I used jolt-jni as my “guinea pig”.
Now that I’ve got a workable automation scheme, I can apply it to Libbulletjme. For 5 months, I’ve been trying and failing to release new versions of Libbulletjme, and that has impacted progress on Minie. For me, this is a big deal!
The motivation for KK Physics v0.3.1 is simply to have a release that works with the latest jolt-jni. It’s still very incomplete and not intended for serious use. I plan to use it primarily for performance testing.
I re-ran these tests with latest Linux Mint (22.1), KK Physics, Minie, and JME (3.8.0-beta2):
(a) Minie single-threaded: 2733 - 2786 boxes
(b) KK Physics with 10 worker threads: 3674 - 3687 boxes (32% - 35% more boxes)
KK Physics with 1 worker thread: 2336 - 2382 boxes
The performance of KK Physics appears to have improved by 5-7%, while that of Minie declined slightly. I suspect the improvement came from changing the compiler options used to build the jolt-jni natives, possibly here.
Again, 33% more boxes doesn’t imply that the physics engine is only 33% more efficient. In the worst case, simulation work increases as the square of the number of bodies.