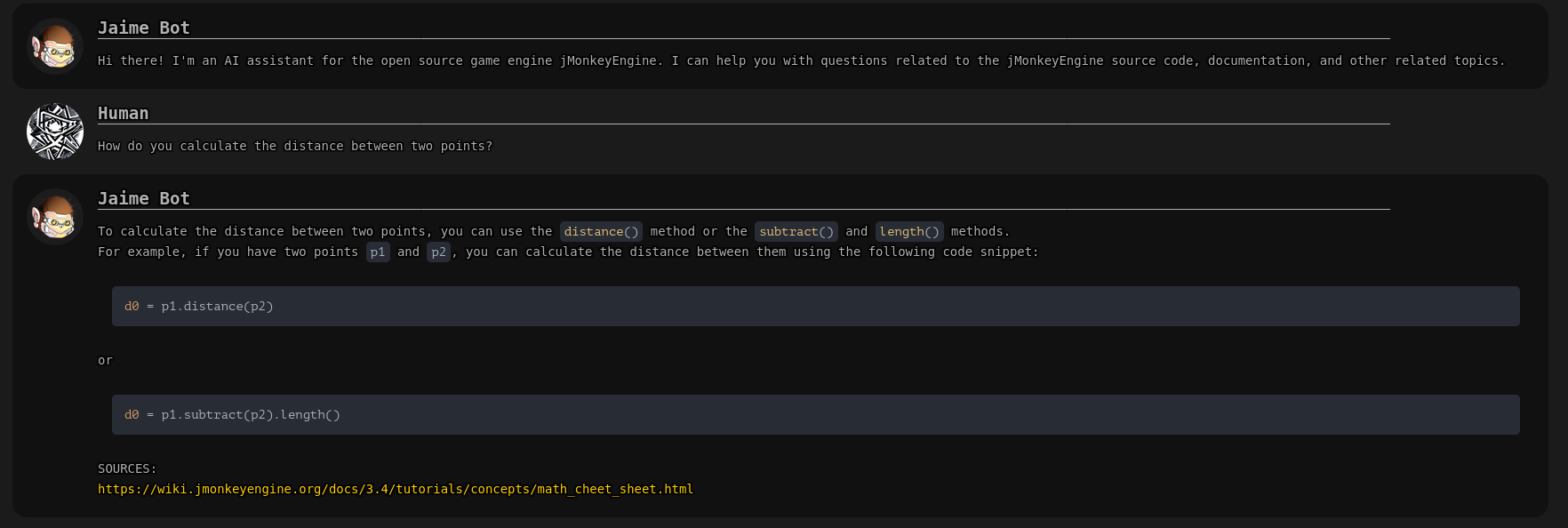
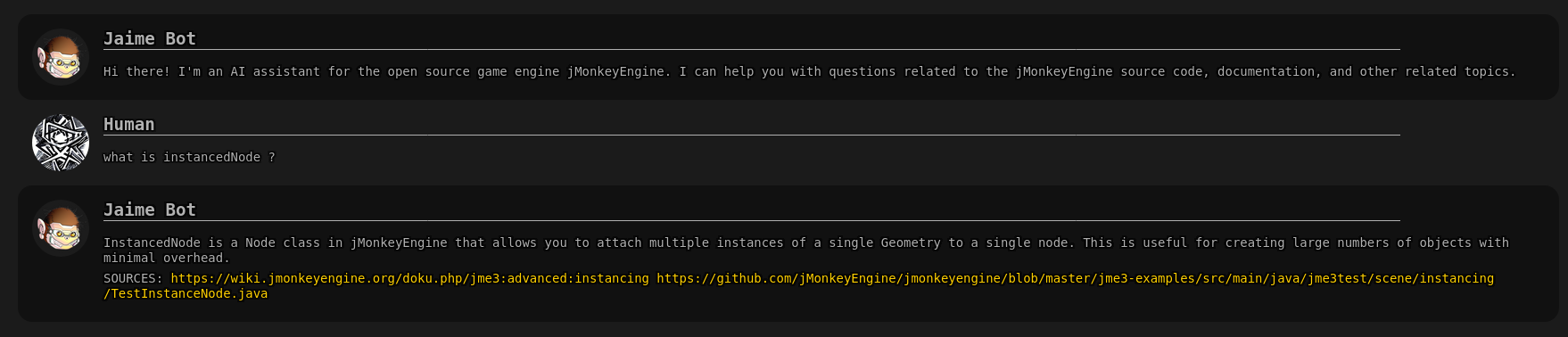
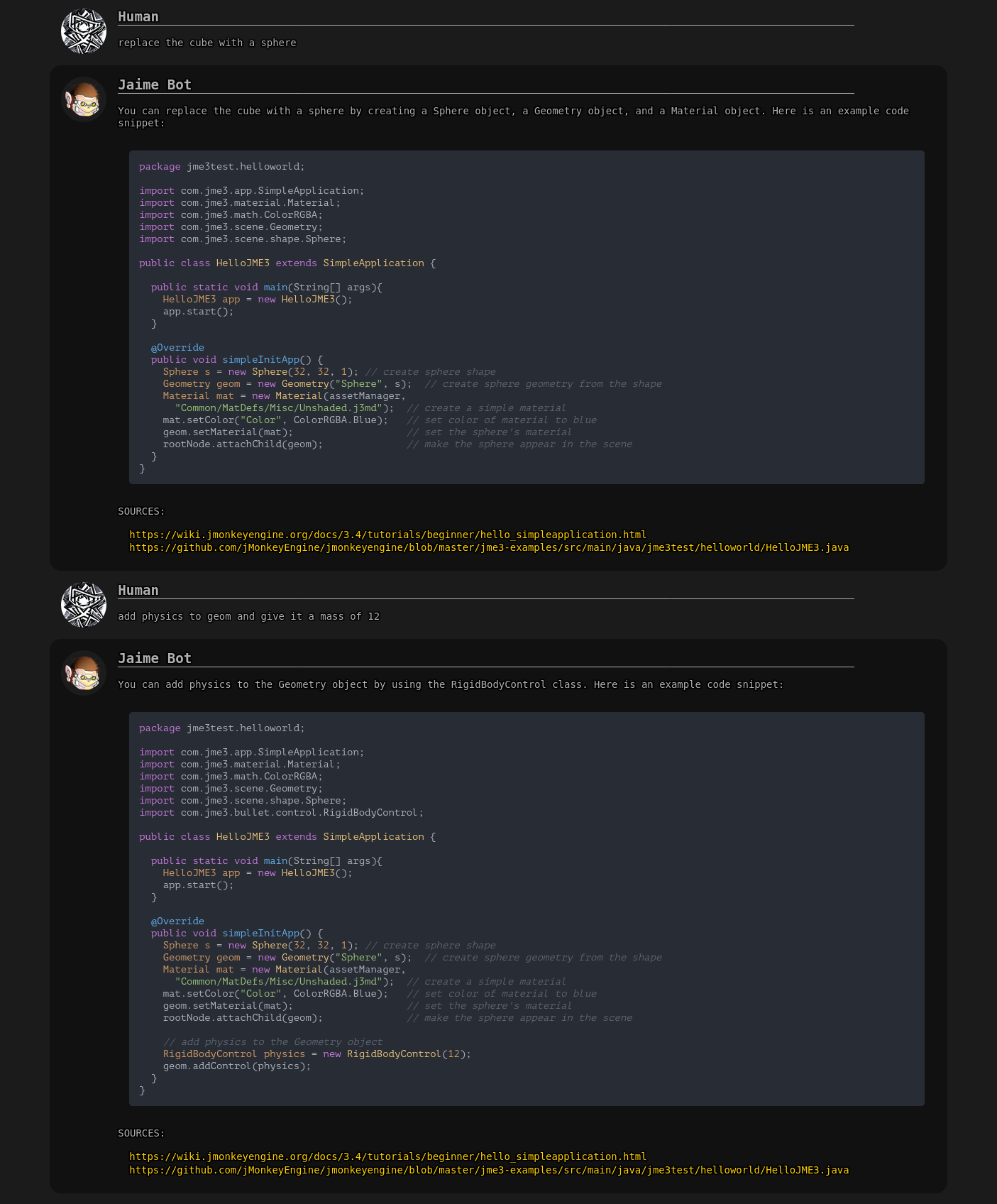
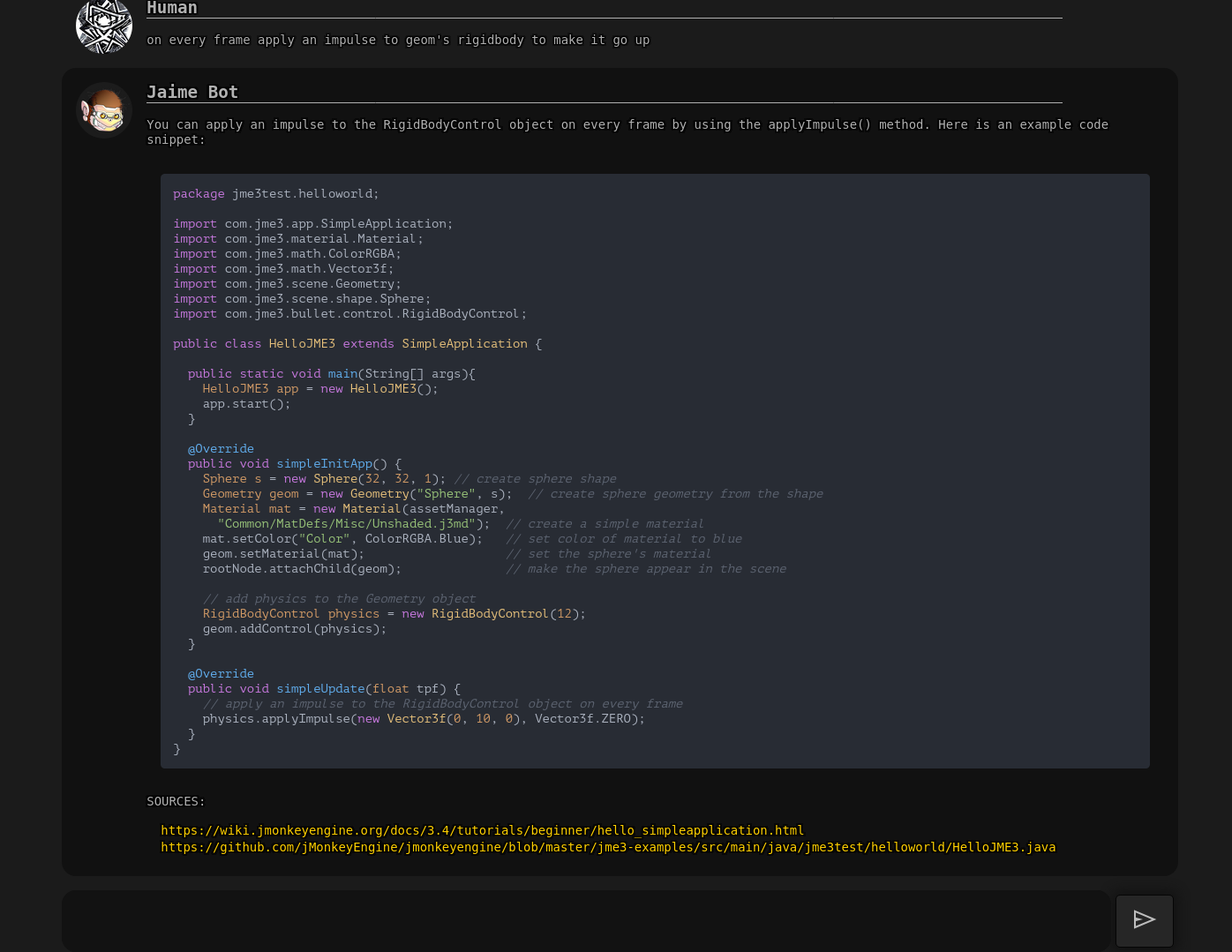
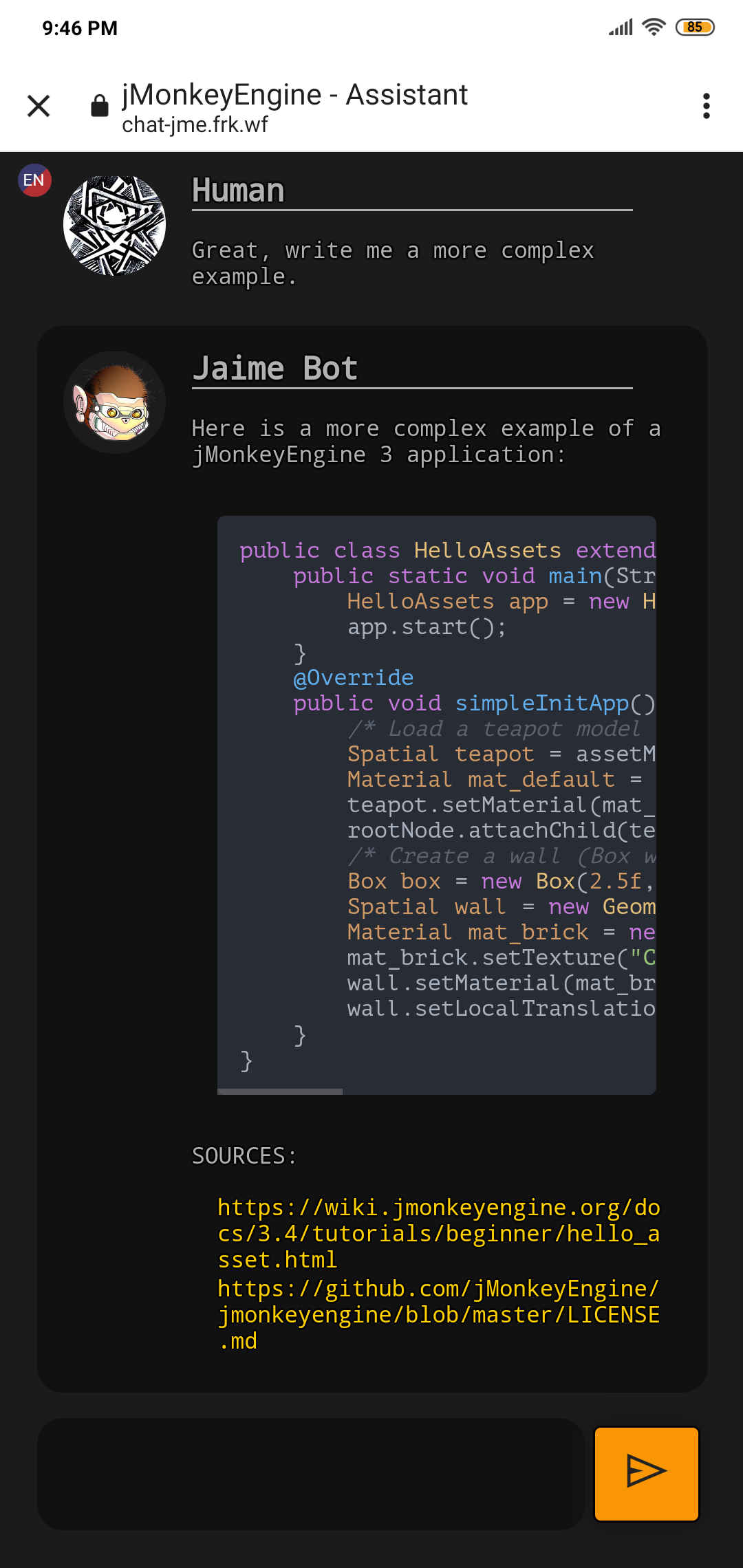
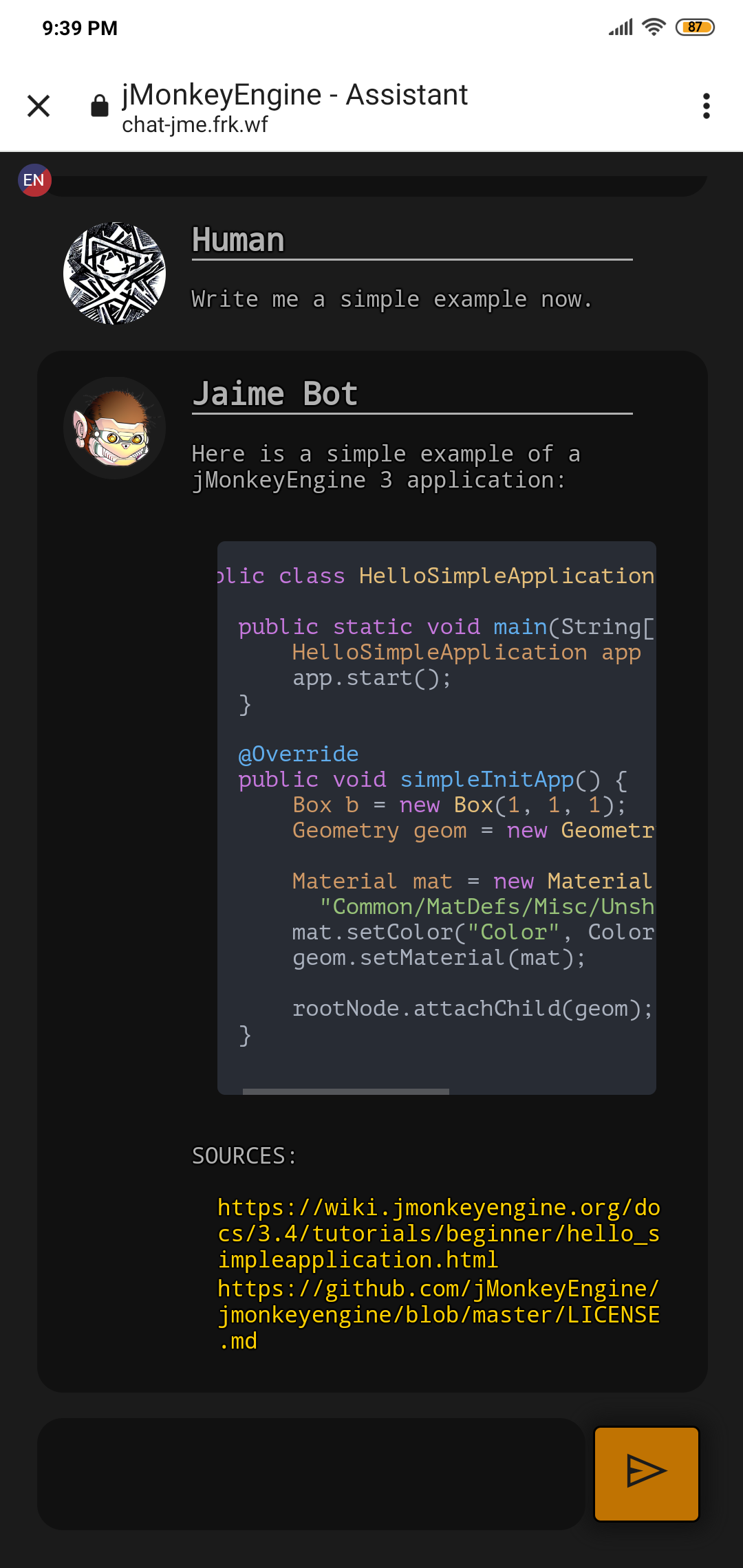
I have created an AI assistant using OpenAI’s GPT-3 APIs and other opensource stuff, with knowledge on topics related to JME.
Autoregressive language models, such as GPT-3, generate text by predicting the next token based on context. Turns out that if they are large enough, they can perform pretty amazing tasks.
To extend the knowledge of the model it is possible to insert pieces of additional information inside the prompt and ask it to respond considering the context, this is usually done by looking though searchable text embeddings and finding the documents closest to the requested information.
That’s how chat-jme works, with the addition of being able to also search the forum in real-time for related topics. obviously the creepy logo is made with ai
Testing
You can test my deployment here (until we hit the usage limit at least): https://chat-jme.frk.wf
Or you can run your own instance from this repo:
(yes, it is python, 90% of the ML libraries are in python, luckily copilot does most of the job these days)
Note: You will need an OpenAI key that you can get preloaded with 18$ of free credit by signing up to https://openai.com/ with a valid phone number.
Since some tasks (summaries and embeedings generation) are executed locally, I recommend to run the bot on cuda GPUs, but it is possible to run it on a decent cpu with slower real-time embeddings generation (for the forum search) and simpler/less accurate summaries.
I’d like to hear your feedbacks.
Improvements
There is a lot of possible improvements and tweaks to improve accuracy, performances and costs, this is my TODO list with links to the related code, feel free to experiment
Try other faster/cheaper LLMs other than OpenAI (didn’t have a lot of luck with that so far, but they might need some tweaks to the prompt to perform better) [1] Note: we are stuck to third party apis since it seems there is no way to run a big enough LLM on consumer hardware atm, unless your consumer hardware has 300 GB of vram
Move all the static embeddings from OpenAI to locally executed MiniLM ( EmbeddingsManager.new(backend="gpu") ) to reduce api calls [1]
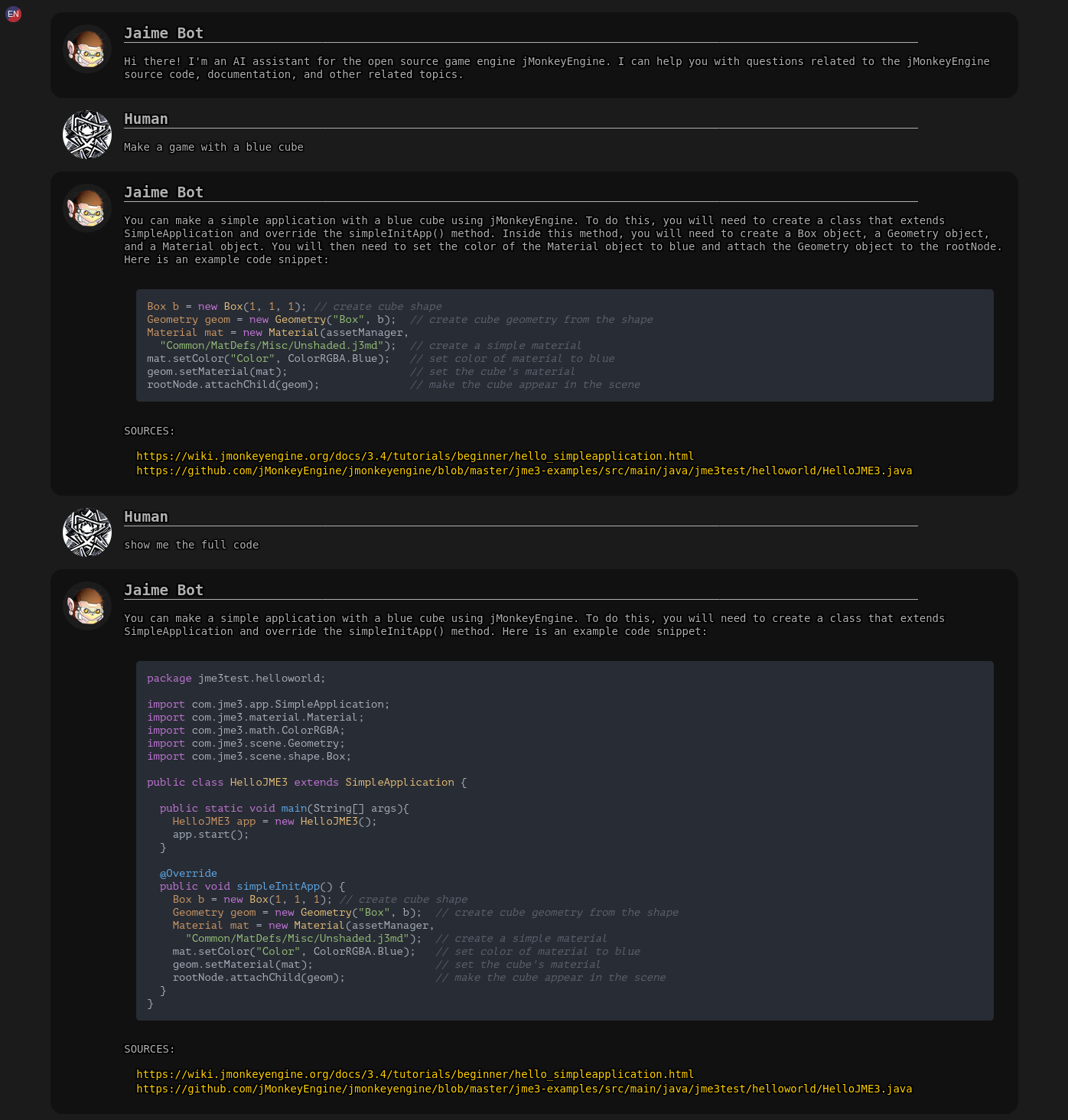
Explore different settings for smartcache or kill it: this is a custom cache layer i’ve added before LLM calls, it basically creates a tree cache using summarization to build increasingly accurate representation of the question + previous context and tries to find a cached answer to a question close enough, you can picture it like this:
q: make a game
q: make a game with a cube
q: make a game with a red cube: a: this is a red cube ....
q: make a game with a blue cube: a: this is a blue cube ....
q: make a game with a sphere
q: make a game with a green sphere: a: this is a green sphere ....
q: make coffee
q: make espresso coffee
q: make espresso coffee of my favorite brand: a: no
Tweaking the settings of the smartcache can make the bot less or more accurate [1a][1b for docker builds][2] .
It also somewhat penalizes performances to save api calls, so it might be worth removing it entirely.
Better static embeddings: I’ve used what was already available on the wikis and github (see here), but the bot might improve its accuracy by reducing the dataset and/or using something designed for it (eg. documented code examples). [1]
Faster forum searches by making solutions: this requires the addition of a plugin to our forum that would allow to mark posts as solution for a topic (like yahoo answer/stackoverflow etc.) that would allow the bot to parse only the first question and solution instead of trying to make sense of the whole topic. [1]
On desktop on chrome Version 108.0.5359.124 (Official Build) (64-bit), the jaime bot avatar is invisible, i have inspected the web, and the image is not there ? it shows 0 bytes:
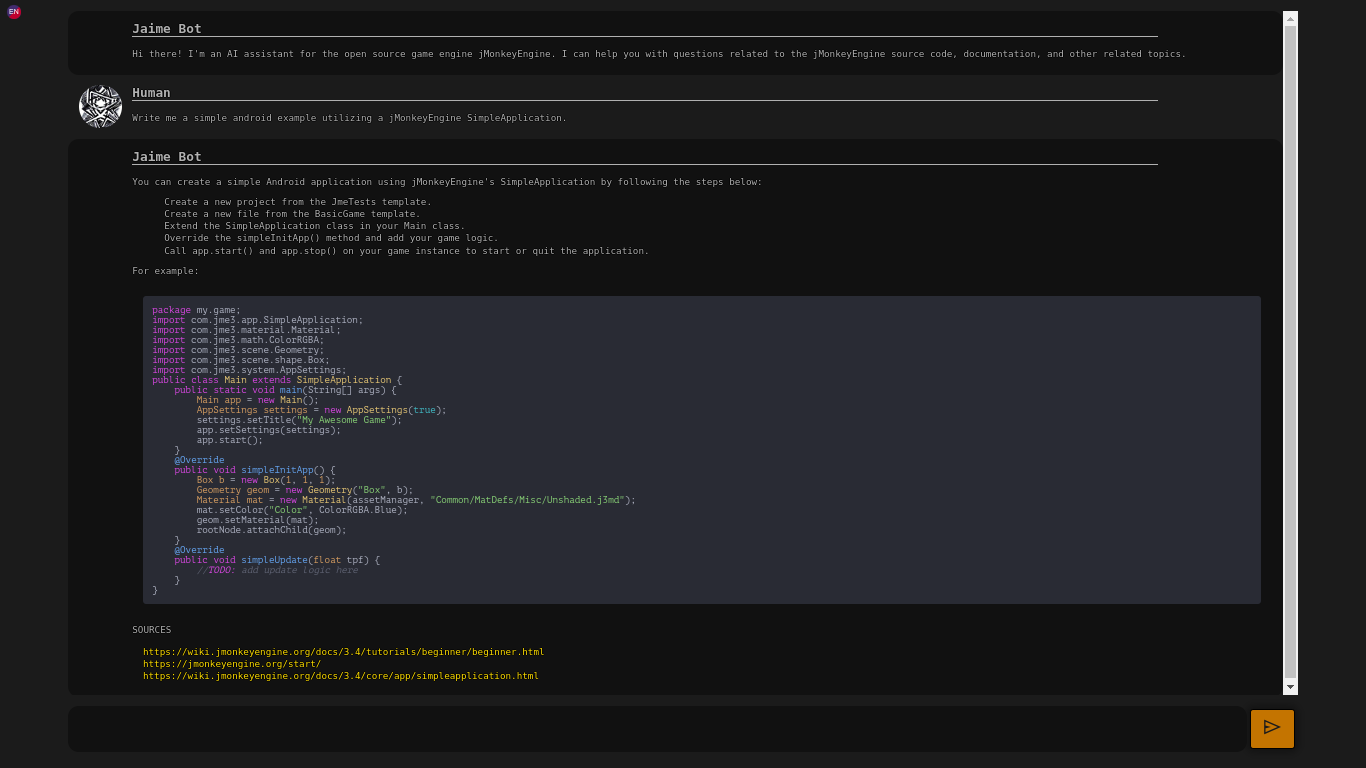
Unfortunately, it has failed to give a full answer for an android example…
Some suggestions:
Decrease the latency (timeout) of the text writing.
May be giving a full answer including the gradle.build will be also a good optimization, but it is not necessary i think since it already links the resources.
Thanks for the feedback and suggestions, the issue with the avatar was probably caused by the image being corrupted at some point during download (maybe server restart or overload?) and cached by chrome, i will implement a fix to avoid that.
That’s a good idea, next time I update the embeddings, I will also include some Gradle (maybe the jme initializer template?) and GLSL code, since currently the bot only knows our Java code, then we will see if GPT can make sense out of it,
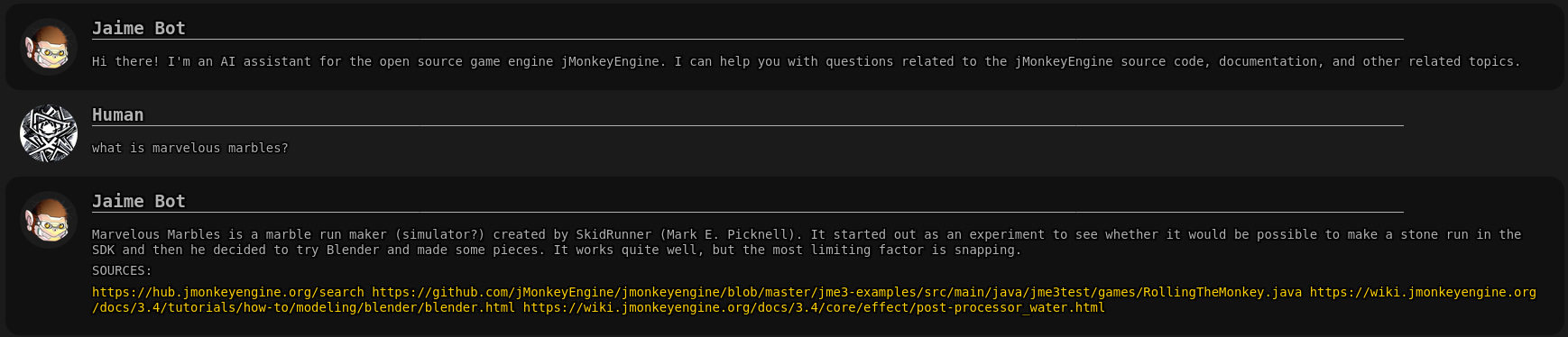
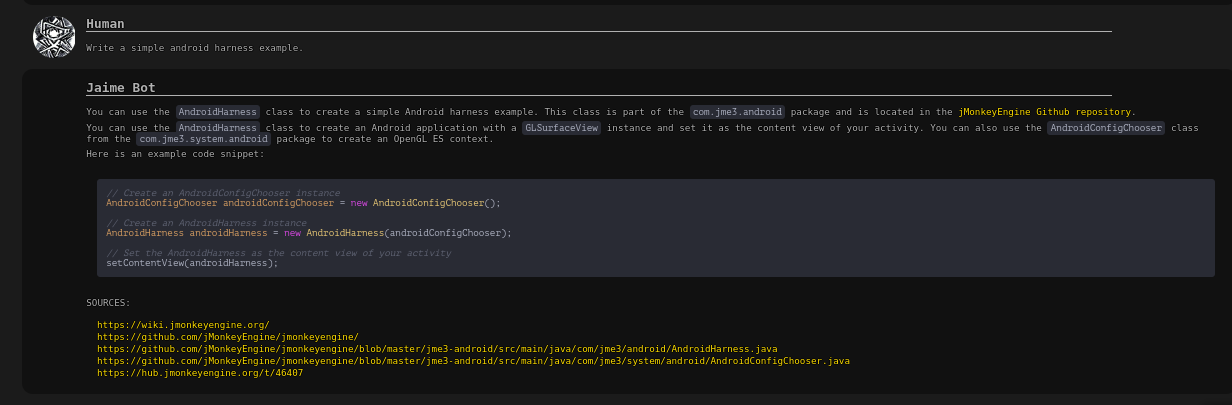
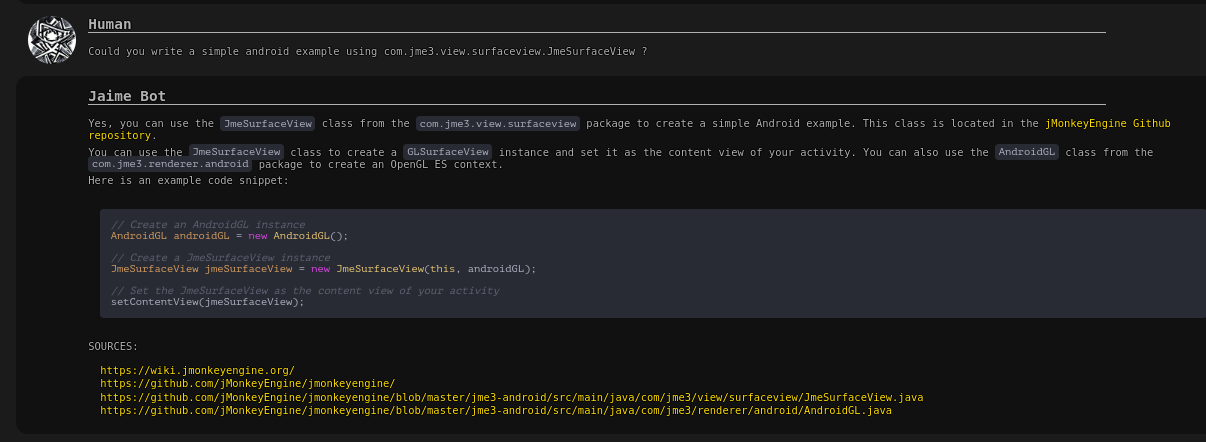
This is the android harness answer, the text is a little-bit off but acceptable, the code is totally wrong, the hub link is wrong too (it links me to the marvelous marbles game).
maybe we need better source material on the wiki for android, it seems the only thing it could find was the code on github.
Not sure why it linked marvelous marbles… maybe it was related to the previous question? It remembers the history of the conversation until the page is reloaded, so doing that sometimes helps when changing topic
I have a repository that lists some android examples, but it is not completed yet (however, basic harness and jmesurfaceview are completed, others as hellolemur are still wip):
EDIT:
You may try to add it to the static embeddings…
I’ve deployed the new version, it took me a lot since for some reason github package registry was closing the connection while downloading the (very big) docker image, so i had to split it into multiple layer and rebuild everything.
Changelog:
Added way to query the bot embeddings: By using the api /docs or through the web ui at https://chat-jme.frk.wf/docs.html it is possible to query the embeddings. The api searches through the knowledge of the bot and returns the documents as they are in memory (it does not process them with the AI). This is mostly there for debug, but it is also possible to use the api to implement a dumber but much faster bot/search engine, might be useful in the future.
Increased typing speed: the typing animation is supposed to be a soft rate limiter built in the ui, but it was indeed a bit too slow and annoying
Added knowledge of gradle files in our repos : it can’t suggest full build scripts yet, this should probably be changed to learn from specific template files, but i will do it in a later update
Added shader files to the knowledge
Added Monkey-Droid-jme3-Simple-Examples : the bot should now know something more about android code
Refresh images when the webui is reloaded : Prevent corrupted images from being cached forever
Rebuilt all embeddings with locally run model: avoid expending openai api calls
Added support for merged embeddings: one big embedding for target = faster generation and lookup. The reason for having many small embeddings was to avoid regenerating all of them that was slow and expensive when using openai apis, this is not the case anymore since when generating them with a model running on gpu takes few minutes and is virtually free
Replaced embedding model with all-mpnet-base-v2 : this is much faster and the quality seems pretty much the same or better
Support batch generation for embeddings
Rebuild all the embeddings
Fixed issue with serialization that caused local embeddings to be too big
Smart cache is now much faster
I’ve seen that (as expected from gpt3…) sometimes the bot responds with plausible bullshit or blatant lies. i will look into making a stricter prompt to try to reduce that.