14 posts were split to a new topic: Loading the bistro scene into JME
Okay, this is my final test.
After correctly setting Trilinear texture filtering for all Geometry, the frame rate increased tremendously due to the reduced total texture bandwidth, as follows:
Spec: RTX2070
Resolution: 1600*900
Lighting: One main light source + one LightProbe
Post Processing: SSAO, ToneMap, Shadow
At this point, JME3’s frame rate reached an astonishing 480FPS… (much higher than Godot, but Godot uses compressed texture formats, so I guess the reason here may be because I batched the scene to reduce Drawcalls):

Then with 200 point lights, SSAO+ToneMap+FXAA+Bloom+VolumeLight. The frame rate reached 160~170 frames, which also exceeded my expectations for this scene:
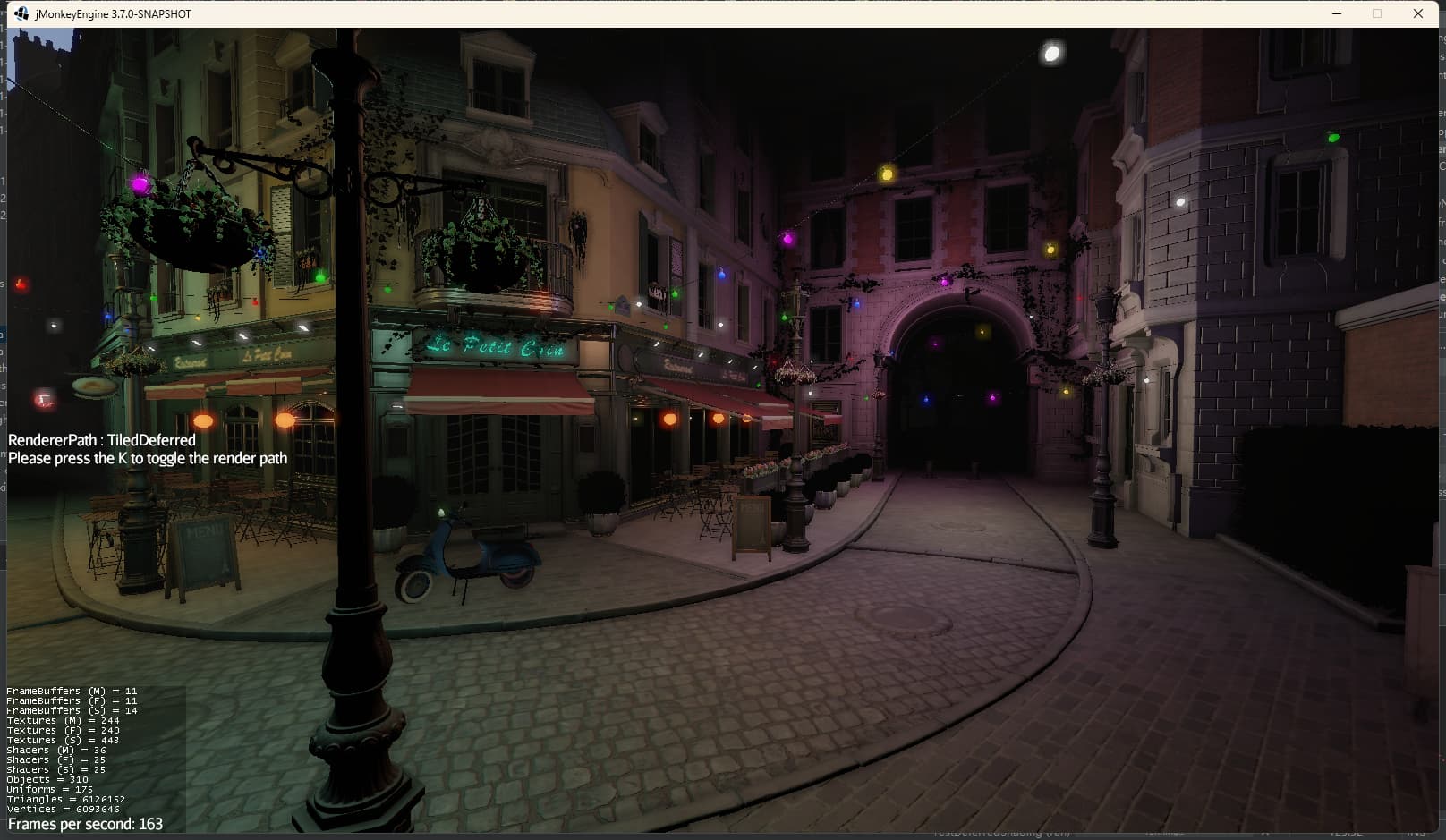
I think JME3’s frame rate will improve further with compressed texture formats.
14 Likes
Thank you JhonKkk for your great work ![]()
Filtering do change a lot it seems wow.
We do not know how many drawCalls Godot had there, but still having much higher frames with simple batch is outstanding.
Tho this time i see Forward one is 480FPS. Forward because no lights in day example right?
I see bottom brick quality still better than Godot even with filtering, tho upper red one looks same now.
I think JME3’s frame rate will improve further with compressed texture formats.
You plan it for 2.0 PR? Hope 1.0 can go in without too much delay.
1 Like
jME supports wide variety of compressed texture formats. We are talking about the DDS container, right? jME supports at least DXT1, DXT3, DXT5, DX10, BC1 - BC7. And I think Riccardo just added a bunch more (mostly for web or mobile…).
1 Like
Yes, with a small number of lights, forward is faster than deferred/tile-based deferred due to the MRT overhead of deferred.
I think that after being merged into the core, for a period of time I will fix some bugs that I did not find but others discovered, while also advancing the work on the global illumination part at the same time. As for further optimizations, I suggest opening a new GitHub issue based on this PR, so that I can optimize them in the future.
1 Like
Compressed texture formats are really important. Basically all commercial games use compressed texture formats rather than jpg and the like, because it significantly optimizes texture bandwidth.
Also, thanks to @RiccardoBlb for the code contribution. Mobile gaming is one of the main platforms I’m focusing on. As far as I know, Adreno and ArmMali both provide their own compressed texture processing .exe for easy third party integration or direct use. For IOS, I’m not sure if it provides SDK or exe tools.
But based on my many years of mobile game development experience on Android, the preferred texture format is ASTC.
4 Likes
Also i didnt noticed you mentioning of using FSR 1.0 in examples, so i guess fps could be even faster when use it. Or maybe it was used?
FSR 1.0 is not included in this PR. The comparison with Godot this time also does not have FSR 1.0. This is a feature to be added in a subsequent PR. ![]()
3 Likes
ok ![]() for sure im looking forward for this feature, its very cool one. (tho idk if important for your personal use, because im not sure if mobile can use it, tho 1.0 probably yes?)
for sure im looking forward for this feature, its very cool one. (tho idk if important for your personal use, because im not sure if mobile can use it, tho 1.0 probably yes?)
1 Like
FSR1.0 can be used on mobile, I have already put it into use in two mobile games (and it’s suitable for low-end devices, like Android devices around 2015 or even 2013), and I see it recommended in the industry as the upscaling technique to improve framerates on mobile.
For deferred rendering, the current tile-based implementation is not very suitable for mobile, or only suitable for very high-end devices. The multi-light rendering solution for mobile is Forward+, however, a better solution would be deferred rendering based on on-chip cache.
4 Likes
So this 1.0 seems to be done now.
Just need wait for release new Engine version?
1 Like
Hi @zzuegg , I don’t remember the specs of your test device before. This is with RTX 2070, 1600*900 resolution, using toneMap + bloom postprocessing. Frame rates when adjusting different TileSize values:
tileSize:32

tileSize:64

tileSize:None
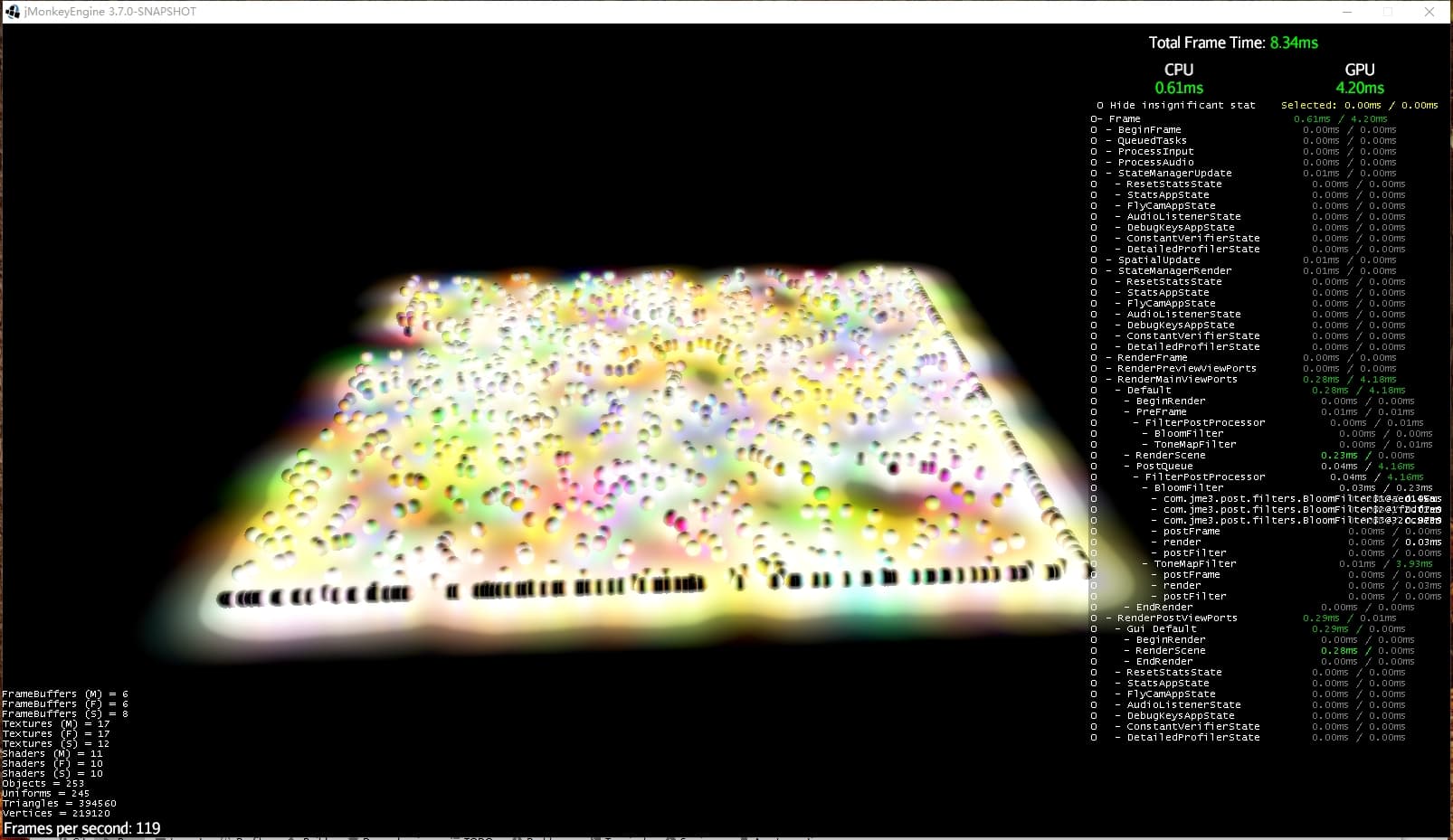
Previously your test may have used a fixed tile size instead of setting tileSize, although the time cost here is still 2.89ms. I analyzed it with NVIDIA Nsight before, since I update 5 large textures every frame, the cost here is around 1.9ms. So if using one-time cache or other methods, the overall time cost could probably be controlled within 1.2ms, this is just my guess.
But I haven’t figured out a good way to optimize the texture cache or use alternative solutions (like SSBO) that is compatible with the upper layer encapsulation. This may be on the list for future optimizations.
I think 3.7 should include global illumination, however I’ve been waiting for this PR to finish, otherwise other contents will keep auto-appending to the back…
1 Like
just after my question i noticed 2 more PR code check comments were added, you might want look at them.
Also for 2.0 (not 1.0):
- might be worth to verify if your LightProbe changes idea might collide with old PR:
Accelerated env baking on the GPU by riccardobl · Pull Request #1165 · jMonkeyEngine/jmonkeyengine · GitHub
1 Like
Thank you,I have reviewed this part of the code and it does not conflict with the new LightProbeVolume system. However, the logic to precompute irradiance data can be reused.
1 Like
I am running a 1080ti and a gen1 threadripper. I think the main performance difference is because illuminas uses a lighter gbuffer because i had not to support different shading techniques.
Also this scene, especially when viewed from the side causes a lot of overdraw in a classic deferred pipeline and a lot of unnecessary calculations in a tile based deferred one. So it is a good stress test but performance should be better in real world usecases. Thats what the clustered variants are trying to solve.
Would be nice if some amd user could try it out because i never trust nvidia. they are too forgiving.
Have you tried lowering the normal render target to 16 or even 8 bit? in combination with the octahedral mapping it should still give plenty of precision. i have seen a paper that 10 bits per channel already gives more precision then a rgb8 version.
Mainly because i think in most usecases when you hit a gpu limit it is going to be bandwith.
Beside that i noticed when you add more shadow casing lights you hit the cpu limit very soon.
That would have been my next optimisation target, because i think there would be room to render lots of shadow casting lights in a deferred pipeline if the culling would not be that expensive
On what engine is the framegraph design based on?
It is now part of my early experience writing a DX11 engine, I will lean towards UE5’s RDG design in the future.
I’m already using octahedral encoding, but NormalRT still remains 32bit. There are many methods to reduce GBuffer size, such as reconstructing Position from depth, approximate normals etc.
However, I probably won’t reduce the GBuffer size, because this may hurt storing other data later (timeline cache, D-buffer data, V-buffer data, as well as Mask, GI information,As you said, normal can be stored at lower bit, but I won’t decrease NormalRT, I will store other contents except Normal in RT 32 bit (but now this RT is only used to store normals).), this may need balancing between engine feature flexibility and performance, but I choose flexibility, because I need more memory to store enough information to implement future contents about SubfaceProfiler, Hair, GI, so sacrificing some performance for more graphical features is worth it.
Regarding overdraw, I currently have no plans to implement RenderPaths like ClusterDeferred, but should implement it when I have time in the future.
I think I won’t use traditional ShadowMaps to implement mass quantity of shadows. I provided some techniques I may use in the future to handle mass quantity of shadows in my reply above, which is to use VirtualTexture and timeline shadow techniques to achieve something like 500 dynamic shadows.
These are some experiments I did early in my personal 3D engine (sorry, gif only allows 1mb upload), the picture shows 1280*720 resolution, including FXAA, Tonemap, Bloom, and about 500+ dynamic PointLightShadows, on my 2070, the framerate stayed at 65-100FPS, it is not based on the standard ShadowMap scheme. I don’t have time to port it to JME3 now, maybe in the future, because I’m not sure if real games really need more than 500+ dynamic shadows (I see most games only have a few main light sources with shadows):




Thank you for providing the reference techniques.
10 Likes
So since it is not configurable, everyone has to pay the price because you might need the rendertargets later on.
This things should really be configuarable, as well as the whole framegraph. that is the point of it.