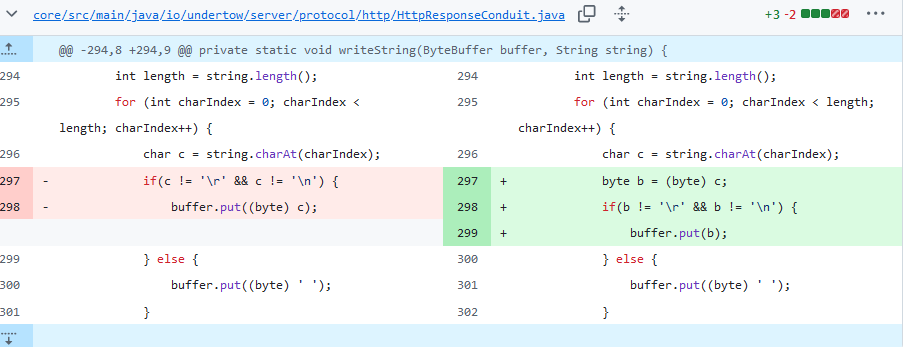
…doesn’t appear related to encoding but is adding a corrupter to the code. Casting a char to a byte shouldn’t actually be doing anything here unless you have some \r or \n ‘characters’ that have the high-order bits set for some reason… but then they wouldn’t have been \r or \n and this code is turning the original characters to garbage because of a coincidence that it happens to share 8 bits with \r or \n.
This isn’t really how to convert characters to bytes in a reversible way.
As for RmiSerializer, similarly, the breakage is more serious. It needs to be writing the actual character values and not chomping them into bytes. The string that is received on the other end is never going to be the same as the string written with the code the way it is. And your fix doesn’t really fix this either… though it’s close. The reverse would have to be done on the read side to turn it back into characters for the string.
Really, RmiSerializer should probably be deprecated. There is a separate service.rmi layer that does a bunch of things better (though is slightly more limiting to better fit what SpiderMonkey is actually doing). The service.rmi layer defers to StringSerializer for strings… which is already doing the right thing: