Hey guys, 
as some of you know I’ve been working on my Vulkan engine from time to time - Since I reached the point where I wanted to implement raycasting/mousepicking on the CPU, I wanted to see how jMonkey sets up its bounding hierarchy.
I quickly found, that meshes ultimately setup a bounding interval hierarchy:
The according class is com.jme3.collision.bih.BIHTree. (In fact, it’s the only CollisionData implementation so far in jME)
I read the code and saw that it’s very close to the description of Wikipedia. I understood the algorithm and what jME does internally, but I can’t seem to make sense of the splitting heuristic that jME uses.
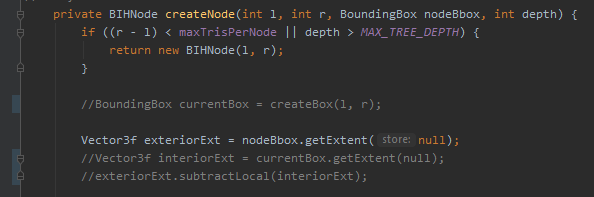
Usually, one uses the longest axis of each “sub-block”/node - This is also what Wikipedia refers to as “Classic”. However, jME passes the “exterior” bounding box (the accoding split of the parents bounding box) and substracts the “interior” (the actual bounding box around the objects in said split) from it. The result is basically the empty/wasted space inside this split (Can even be negative if the actual submesh overflows it because of a previous split decision, just for information). It then chooses the longest axis of that delta boundingbox to decide which axis to take for the next split.
I don’t understand why a bigger “gap” to the exterior bounding box would mean a better split axis.
(Technically, what it also does is avoiding axes, that have overflowing triangles (interior being bigger then exterior → negative delta), but again, since it then just takes one of the 0-distance-to-exterior axes, I don’t see how it would be better than simply picking the longest axis of the actual “submesh” bounds)
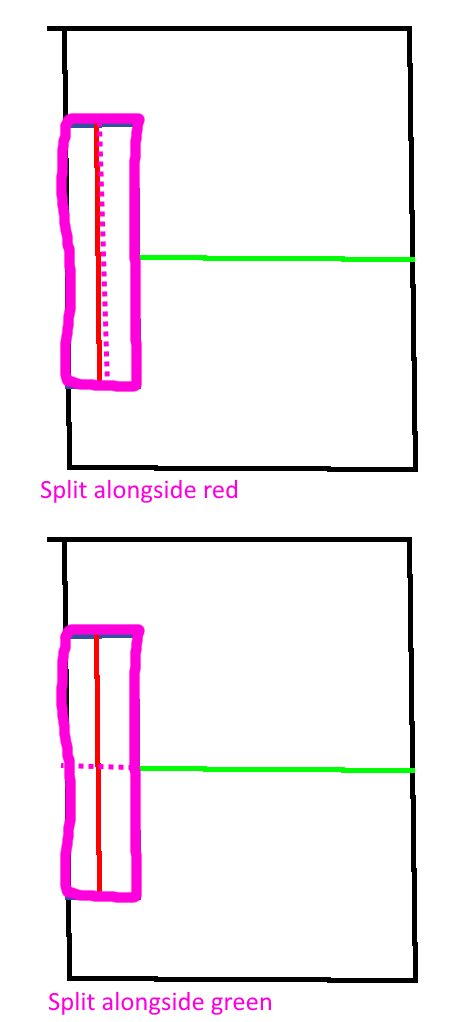
I painted a picture:
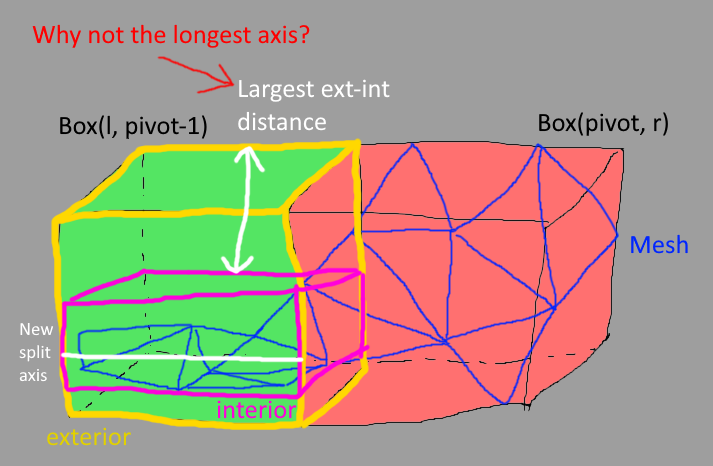
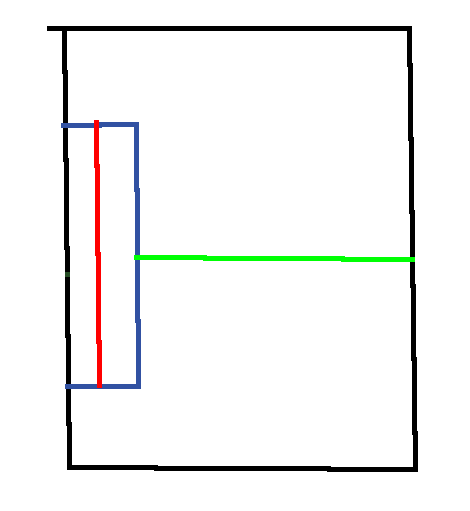
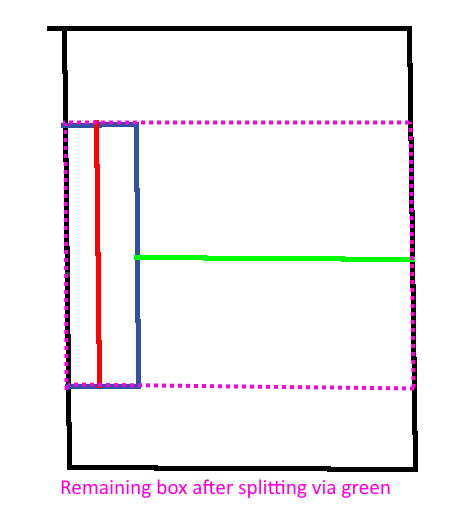
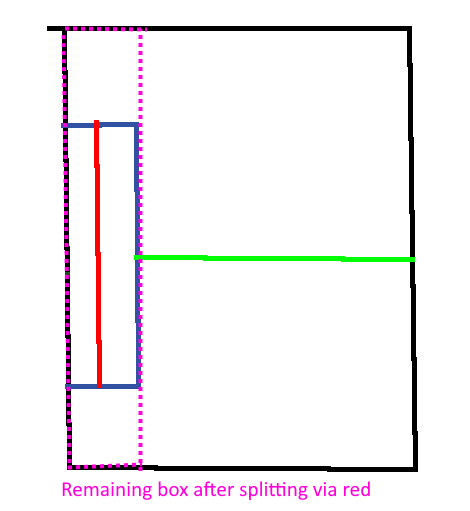
You can see a long (or imagine an even longer) (in “X” direction) submesh inside the split, but because the longet distance to the exterior bounding box would be on the “Z” axis, it would make the next split based on the “Z” axis. This is most likely suboptimal, because (I think) it’s more likely that stuff like rays are checked along the “long” side. Imagine a user clicking on this object - I would say it’s more likely that we omit more unnecessary triangles to check if we split along the “X” axis, because the object probably has more triangles alongside longer axes.
The according place in the code is here:
So basically the classic approach (which would be the one I would’ve used instinctly) would be to just check the longest axis of “interiorExt” instead of “exteriorExt.subtract(interiorExt)”.
I don’t know if anyone who worked on this (I assume this is around from the days of Kirill, Remy, Normen, etc.) is still here to remember if there was a reasoning behind this or if it was unintentional (Sadly there is no @author in the Java class) - Remember that this is only the decision on which axis to split the “submesh”. Even if it’s a suboptimal one, the “submesh” is always divided at the center on that axis, so it’s never toooooooo bad - But still, it seems suboptimal. What confuses me the most, is that I find very little information on the term “BIH” on the internet, only about BVHs. This coupled with the fact that the variable names and algorithm seem very similar to the Wikipedia entry makes me think, that this was written based on the Wikipedia page. Which makes it even weirder that such a special heuristic was used. Especially, because you would need to specifically pass the exterior bounding box to the according method to calculate this. So I’m not sure that it is unintentional…
Maybe someone from the current core team has an opinion on this or can provide some clarity.
If I have time, I will play around with the jME sourcecode and see if I can provide some test results if the classic heuristic has better results (although it’s hard to say stuff like this in general, because you can always be lucky/unlucky with the mesh).
Best regards and thanks a lot for any feedback
 )
)


 Especially because it simplifies the whole code (jME modified the functions ray parameter “in-place”, and then restored the original values at the end of the function and other ugly stuff…)
Especially because it simplifies the whole code (jME modified the functions ray parameter “in-place”, and then restored the original values at the end of the function and other ugly stuff…)